Les avantages des progrès technologiques sont apparemment infinis. Nous pouvons vérifier la sécurité de nos maisons à partir de nos téléphones, recevoir des livraisons de produits alimentaires par drone et même conduire des voitures capables de se garer en parallèle à notre place. Nos téléviseurs sont tout aussi perfectionnés, offrant des choix de contenus apparemment infinis dans un paysage de plateformes et de chaînes qui ne cesse de s'élargir. Pourtant, malgré les nombreuses portes que les téléviseurs intelligents ouvriront dans les années à venir, ils ne seront pas en mesure, à eux seuls, de fournir à l'industrie des médias une vision précise de ceux qui les utilisent.
Les téléviseurs intelligents ont envahi le rayon des téléviseurs de votre grande surface locale. Aujourd'hui, il est difficile de trouver dans un magasin un téléviseur qui ne soit pas connecté à l'internet. Et comme tous les appareils connectés, les téléviseurs intelligents contribuent à la prolifération croissante des données générées par les utilisateurs : Les données de reconnaissance automatique de contenu (ACR) sont la technologie utilisée par les équipementiers pour enregistrer les réglages des téléviseurs intelligents. Combinées à des informations qui détaillent le comportement représentatif d'une personne, ces données font progresser de manière significative la science de la mesure d'audience.
Compte tenu de l'adoption généralisée des téléviseurs intelligents et des données qu'ils produisent, il n'est pas surprenant qu'un grand nombre d'entreprises se tournent vers les données de l'ACR pour mesurer l'audience. Du point de vue de l'échelle, l'opportunité est très attrayante. Cependant, aussi lucrative que soit la source de données ACR, elle ne suffit pas à elle seule à mesurer les audiences, tout simplement parce qu'il lui manque l'aspect le plus important de la mesure d'audience : les personnes. Outre le fait qu'elles ne sont pas représentatives - ou qu'ellesne savent même pas si quelqu'un regarde réellement ce qui est affiché à l'écran - les données ACR présentent un défaut de validation critique : elles exigent que le fabricant de l'appareil fasse correspondre l'image affichée à l'écran avec une image de référence afin de déterminer le contenu qui est affiché. La meilleure façon de libérer le véritable potentiel des données ACR est donc de les calibrer avec des données qui reflètent un véritable comportement de visualisation au niveau de la personne.
Lorsqu'elle fonctionne comme prévu, la technologie ACR surveille les images projetées sur la vitre du téléviseur et les utilise pour déduire le contenu affiché. Les images fournies par l'ACR agissent à bien des égards comme une empreinte digitale du contenu. Mais après avoir recueilli les "empreintes digitales", la technologie doit déterminer sur quel réseau ou plateforme l'image est apparue, ainsi que le moment où elle est apparue. Pour ce faire, la technologie doit faire correspondre l'image à l'écran avec une image contenue dans une bibliothèque de référence gérée par le fabricant.
Il y a trois résultats possibles lorsque la technologie tente d'établir cette correspondance :
- L'image correspond à une seule entrée dans la bibliothèque de référence
- L'image correspond à plusieurs entrées de la bibliothèque de référence
- L'image correspondante ne se trouve pas dans la bibliothèque de référence.
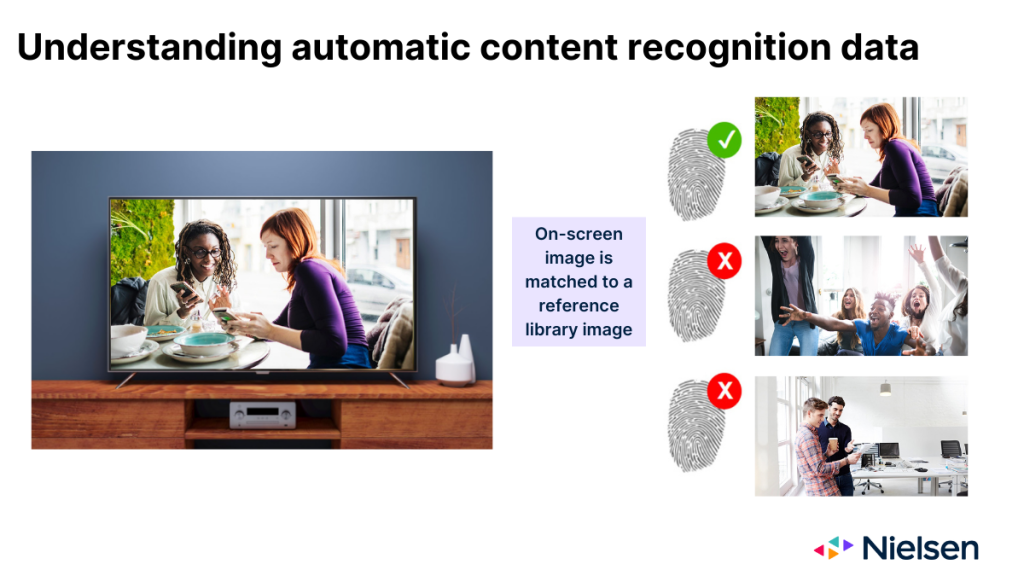
Pour toutes les parties concernées, le premier résultat est le scénario idéal. Le deuxième scénario est moins idéal et s'accompagne d'un certain niveau de risque d'erreur de crédit, simplement en raison des diverses raisons des correspondances multiples (par exemple, diffusions sur plusieurs réseaux, rediffusions, diffusions simultanées). Dans le troisième scénario, personne n'est crédité, ce qui est évidemment le scénario le moins souhaitable. La raison la plus fréquente de ce résultat est que le contenu a été diffusé sur un réseau que l'équipementier ne surveille pas.
Même si la comparaison d'images était une solution de mesure autonome viable, il ne serait jamais possible de l'exploiter en tant que telle. Comme vous pouvez l'imaginer, le coût de la maintenance d'une bibliothèque de chaque image de chaque événement télévisé n'est pas une mince affaire. C'est aussi une tâche qui augmentera de façon exponentielle à perpétuité. Il n'existe pas non plus de délais de conservation standard pour les images.
Alors, comment savoir si la technologie de l'ACR permettra d'obtenir le bon résultat ? En l'absence d'un mécanisme capable de combler les lacunes, nous ne le savons pas. C'est pourquoi Nielsen a investi dans des filigranes, qui sont beaucoup plus déterministes que les signatures, ainsi que dans des sauvegardes de signatures pour chaque flux mesuré. Cela permet de représenter l'ensemble du contenu et de combler les lacunes associées au big data en lui-même. Une fois ces lacunes comblées, les big data provenant de sources telles que l'ACR offrent l'avantage de l'échelle dans un paysage médiatique de plus en plus segmenté. Et lorsque nous utilisons des contrôles de pondération pour calibrer les big data avec des données de visionnage au niveau de la personne, nous sommes en mesure de voir des points de comparaison qui seraient autrement vides.
Dans une étude récente, Nielsen a cherché à comprendre dans quelle mesure ces lacunes dans les bibliothèques de référence affectent les journaux de réglage de l'ACR - la base de la mesure basée sur l'ACR. Dans une analyse des foyers communs réalisée en septembre 2021, nous avons analysé les données de nos deux partenaires fournisseurs d'ACR afin de comprendre où les écarts entre les bibliothèques de référence pouvaient influer sur les mesures. Dans notre étude, nous avons examiné à la fois la concentration des sources de visionnage et les minutes visionnées à partir des sources disponibles.
Toutes sources confondues, nous avons constaté que nos partenaires fournisseurs d'ACR ne surveillent que 31% des stations disponibles. Cela signifie qu'ils ne conservent pas de données dans leurs bibliothèques de référence pour 69% des stations. Lorsque nous avons examiné les minutes visionnées, nous avons constaté que 23 % des minutes provenaient de stations qui ne sont pas surveillées. Cela signifie que les entreprises qui utilisent uniquement les données de l'ACR pour leurs mesures sous-estiment de 23 % les impressions au niveau des ménages.
Malgré les limites des données de l'ACR, nous comprenons l'opportunité d'échelle et de portée qu'elles offrent en tant que source supplémentaire de couverture - similaire à celle des données de trajectoire de retour (RPD) provenant des décodeurs, que notre stratégie big data calibre également avec des données de panel pour répondre à des limites comparables. En intégrant des ensembles de big data à nos données de visionnage, qui fournissent des mesures représentatives de l'ensemble des États-Unis, nous sommes en mesure d'augmenter considérablement la taille de nos échantillons tout en appliquant des méthodologies rigoureuses de science des données pour combler les lacunes et assurer une représentation équitable de l'ensemble de l'audience américaine sur tous les réseaux et toutes les plates-formes.
Une version de cet article a été publiée à l'origine sur AdExchanger.