Os benefícios do avanço da tecnologia são aparentemente infinitos. Podemos verificar a segurança de nossas casas por meio de nossos telefones, receber entregas de supermercado por drones e até mesmo dirigir carros que podem estacionar em paralelo para nós. Nossas TVs estão se tornando igualmente avançadas, oferecendo opções de conteúdo aparentemente infinitas em um cenário cada vez maior de plataformas e canais. No entanto, apesar das muitas portas que as TVs inteligentes abrirão nos próximos anos, elas não serão capazes, por si só, de fornecer ao setor de mídia uma visão precisa de quem as está usando.
As Smart TVs tomaram conta do corredor de TVs do grande varejista local. Hoje em dia, é difícil encontrar uma TV em uma loja que não esteja conectada à Internet. E, assim como todos os dispositivos conectados, as smart TVs contribuem para a crescente proliferação de dados gerados pelo usuário: Os dados de reconhecimento automático de conteúdo (ACR) são a tecnologia que os OEMs usam para capturar a sintonia nas smart TVs. Quando combinados com informações que detalham o comportamento representativo em nível pessoal, esses conjuntos de dados avançam significativamente a ciência da medição de audiência.
Dada a ampla adoção de smart TVs e os dados que elas produzem, não é de surpreender que uma série de empresas esteja buscando os dados ACR como forma de medir o público. Do ponto de vista da escala, a oportunidade é muito atraente. No entanto, por mais lucrativa que seja a fonte de dados ACR, ela não é suficiente por si só para medir audiências, simplesmente porque não possui o aspecto mais importante da medição de audiências: as pessoas. Além de não serem representativos - oumesmo de não saberem se alguém está realmente assistindo ao que está na tela -, os dados de ACR têm uma falha crítica de validação: exigem que o fabricante do dispositivo combine a imagem na tela com uma imagem de referência para determinar o conteúdo que está sendo exibido. Portanto, a melhor maneira de desbloquear o verdadeiro potencial dos dados ACR é calibrá-los com dados que reflitam o verdadeiro comportamento de visualização em nível pessoal.
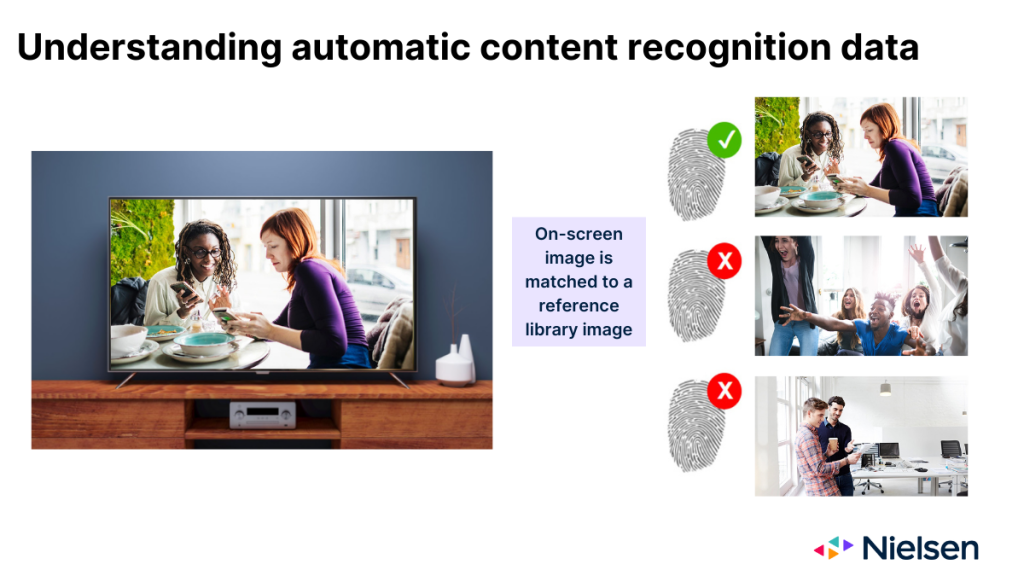
Quando funciona conforme projetado, a tecnologia ACR monitora as imagens que são projetadas no vidro da TV e usa essas imagens para inferir qual conteúdo está sendo exibido. As imagens que o ACR fornece funcionam, em muitos aspectos, como uma impressão digital do conteúdo. Mas depois de coletar as "impressões digitais", a tecnologia precisa determinar em qual rede ou plataforma a imagem apareceu, bem como quando ela apareceu. Para fazer essa determinação, a tecnologia precisa fazer a correspondência da imagem na tela com uma imagem contida em uma biblioteca de referência mantida pelo fabricante.
Há três resultados possíveis quando a tecnologia tenta fazer essa correspondência:
- A imagem corresponde a uma única entrada na biblioteca de referência
- A imagem corresponde a várias entradas na biblioteca de referência
- A imagem correspondente não está na biblioteca de referência
Para todas as partes envolvidas, o primeiro resultado é o cenário ideal. O segundo cenário é menos ideal e apresenta algum nível de risco de crédito errôneo, simplesmente por causa dos vários motivos para as múltiplas correspondências (por exemplo, transmissões entre redes, repetições de transmissões, transmissões simultâneas). No terceiro cenário, ninguém recebe crédito, o que é obviamente o cenário menos desejável. O motivo mais comum para esse resultado é que o conteúdo foi ao ar em uma rede que o OEM não monitora.
Mesmo que a correspondência de imagens fosse uma solução de medição autônoma viável, a capacidade de aproveitá-la como tal nunca seria viável. Como você pode imaginar, o custo para manter uma biblioteca de cada quadro de cada evento na televisão não é uma tarefa pequena. É também uma tarefa que crescerá exponencialmente de forma perpétua. Também não há períodos de retenção padrão para imagens.
Então, como sabemos que a tecnologia ACR fará a correspondência correta? Sem um mecanismo que possa preencher os espaços em branco, não sabemos. É por isso que a Nielsen investiu em marcas d'água, que são muito mais deterministas do que as assinaturas, bem como em backups de assinaturas para cada feed medido. Isso proporciona a representação de todo o conteúdo - preenchendo as lacunas associadas ao big data por si só. Com essas lacunas preenchidas, o big data proveniente de fontes como o ACR oferece o benefício da escala em um cenário de mídia cada vez mais segmentado. E quando usamos controles de ponderação para calibrar o big data com dados de visualização no nível da pessoa, conseguimos ver pontos de comparação que, de outra forma, estariam em branco.
Em um estudo recente, a Nielsen procurou entender o grau em que essas lacunas nas bibliotecas de referência afetam os registros de sintonia do ACR - a base para a medição baseada no ACR. Em uma análise de lares comuns realizada em setembro de 2021, analisamos os dados de nossos dois parceiros provedores de ACR para entender onde as lacunas nas bibliotecas de referência podem influenciar a medição. Em nosso estudo, analisamos a concentração de fontes de visualização e os minutos visualizados das fontes disponíveis.
Em todas as fontes de visualização, descobrimos que nossos parceiros provedores de ACR monitoram apenas 31% das estações disponíveis. Isso significa que eles não mantêm dados em suas bibliotecas de referência para 69% das estações. Quando analisamos os minutos visualizados, descobrimos que 23% dos minutos vieram de estações que não são monitoradas. Isso significa que as empresas que utilizam apenas os dados do ACR para medição estariam subestimando as impressões em nível doméstico em 23%.
Apesar das limitações dos dados ACR por si só, entendemos a oportunidade de escala e alcance que eles oferecem como uma fonte adicional de cobertura - semelhante à dos dados de caminho de retorno (RPD) dos decodificadores, que nossa estratégia de big data também calibra com dados de painel para tratar de limitações comparáveis. Ao integrar conjuntos de big data com nossos dados de visualização, que fornecem medições representativas do total dos EUA, podemos aumentar significativamente nossos tamanhos de amostra e, ao mesmo tempo, aplicar metodologias rigorosas de ciência de dados para preencher as lacunas e garantir uma representação justa do público total dos EUA em todas as redes e plataformas.
Uma versão deste artigo foi publicada originalmente no AdExchanger.